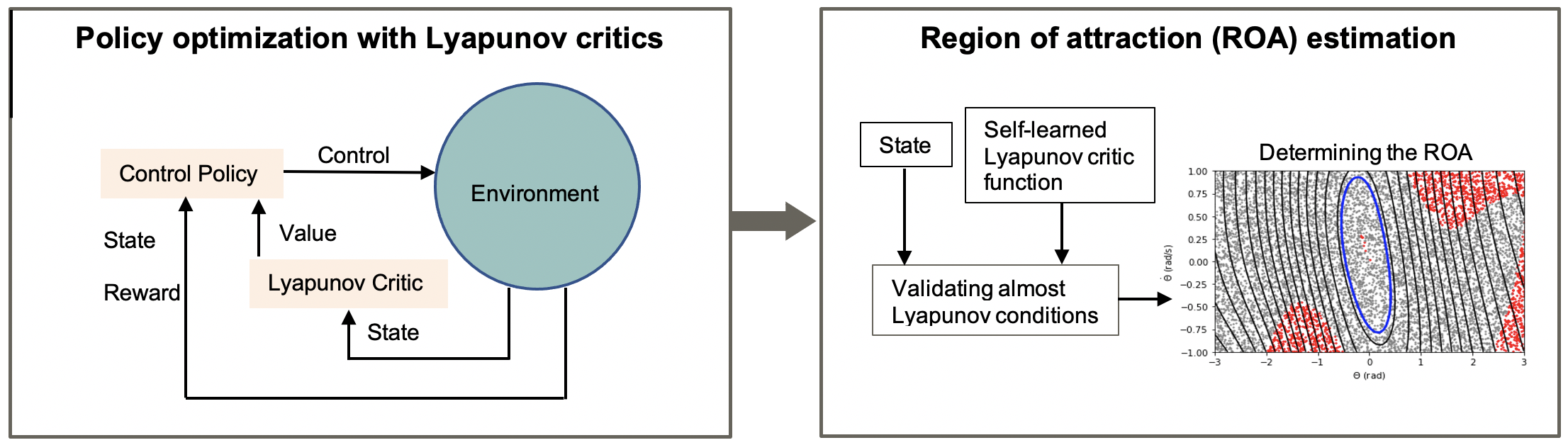
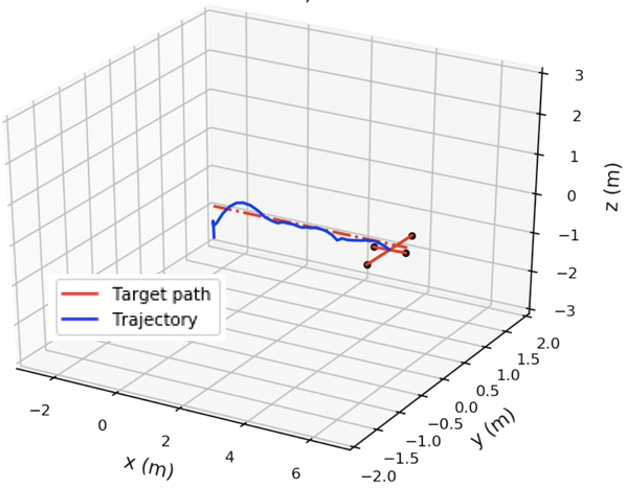
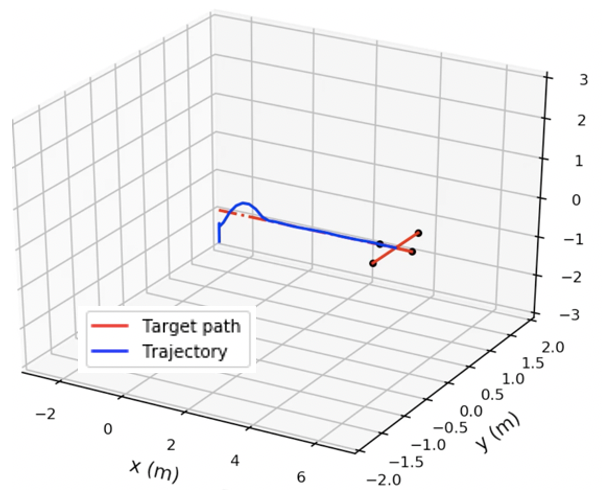
Overall algorithm:
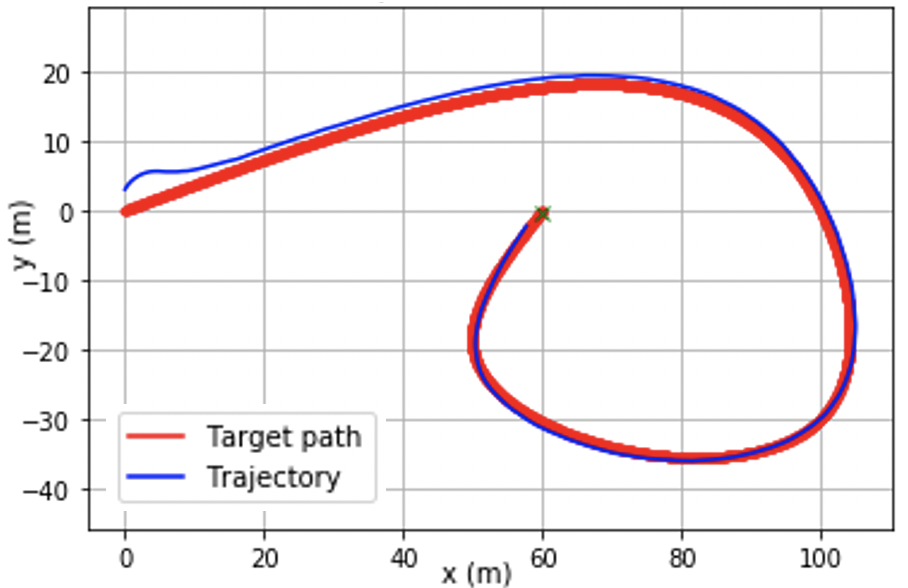
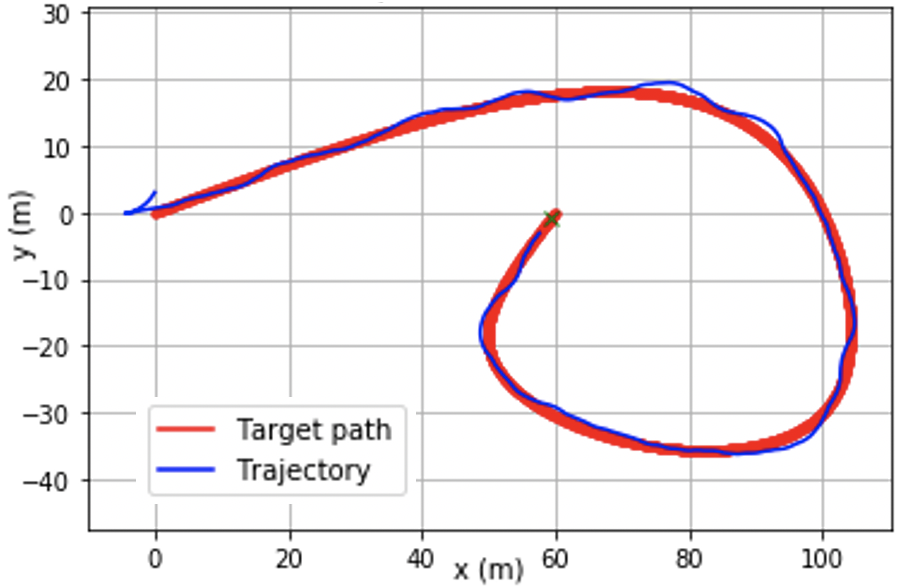
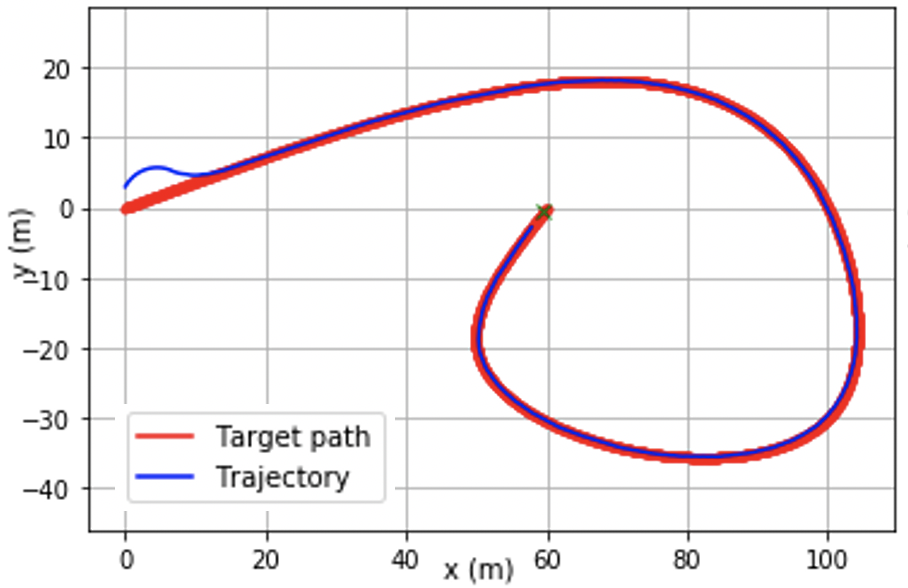
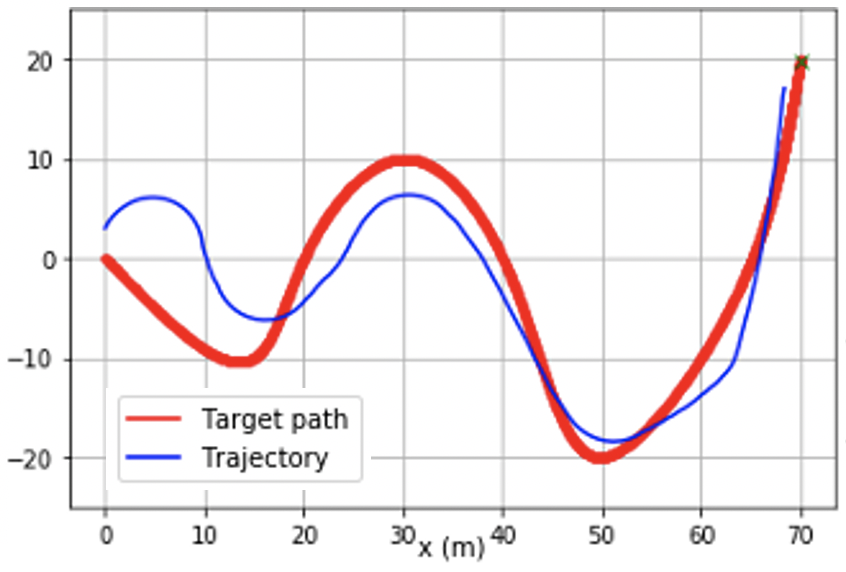
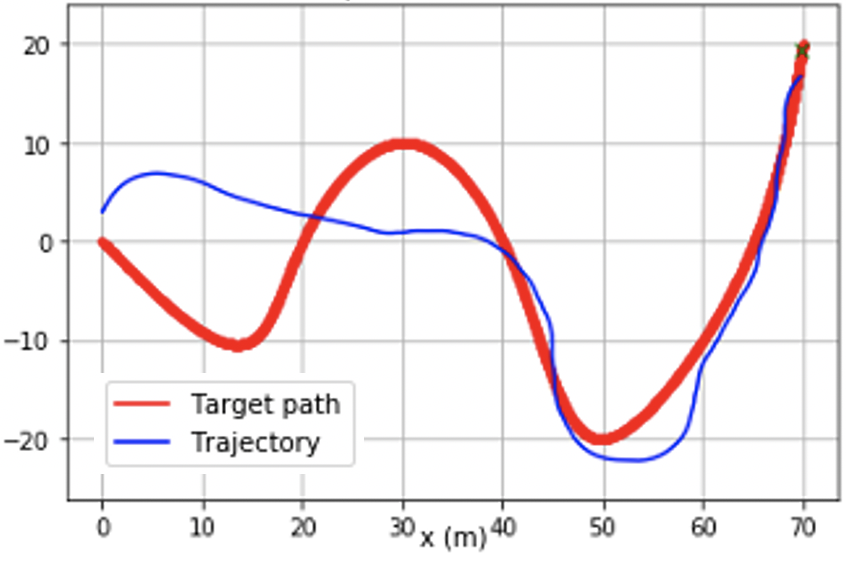
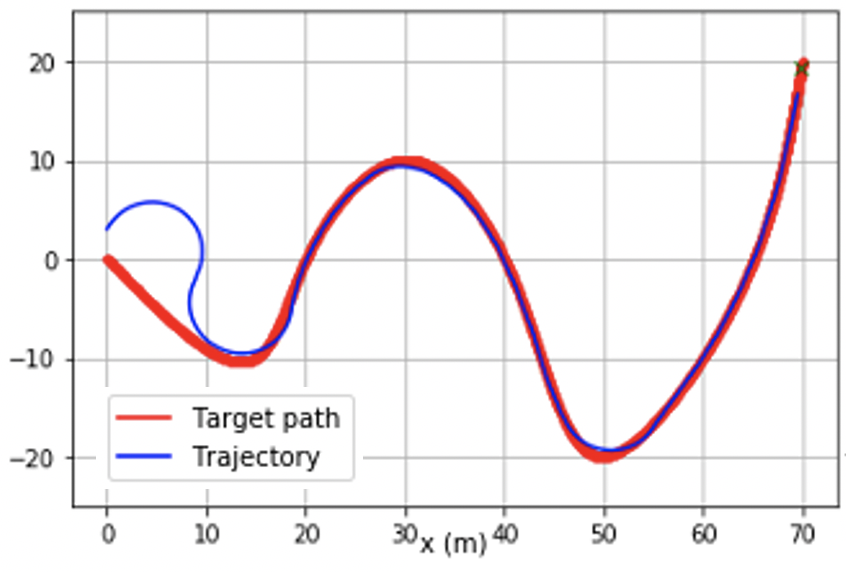
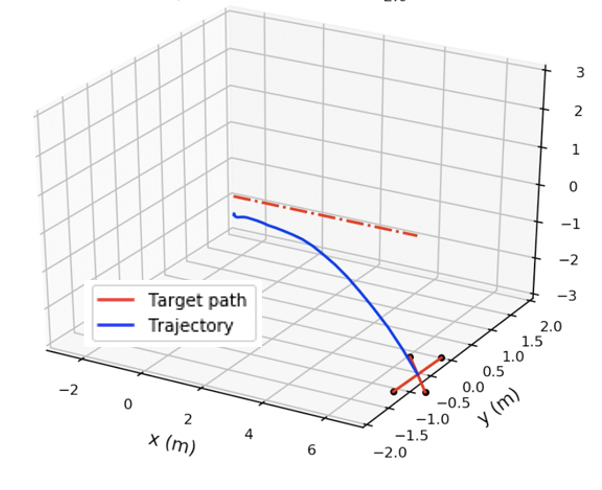
@inproceedings{chang2021stabilizing,
title={Stabilizing neural control using self-learned almost Lyapunov critics},
author={Chang, Ya-Chien and Gao, Sicun},
booktitle={2021 IEEE International Conference on Robotics and Automation (ICRA)},
pages={1803--1809},
year={2021},
organization={IEEE}
}