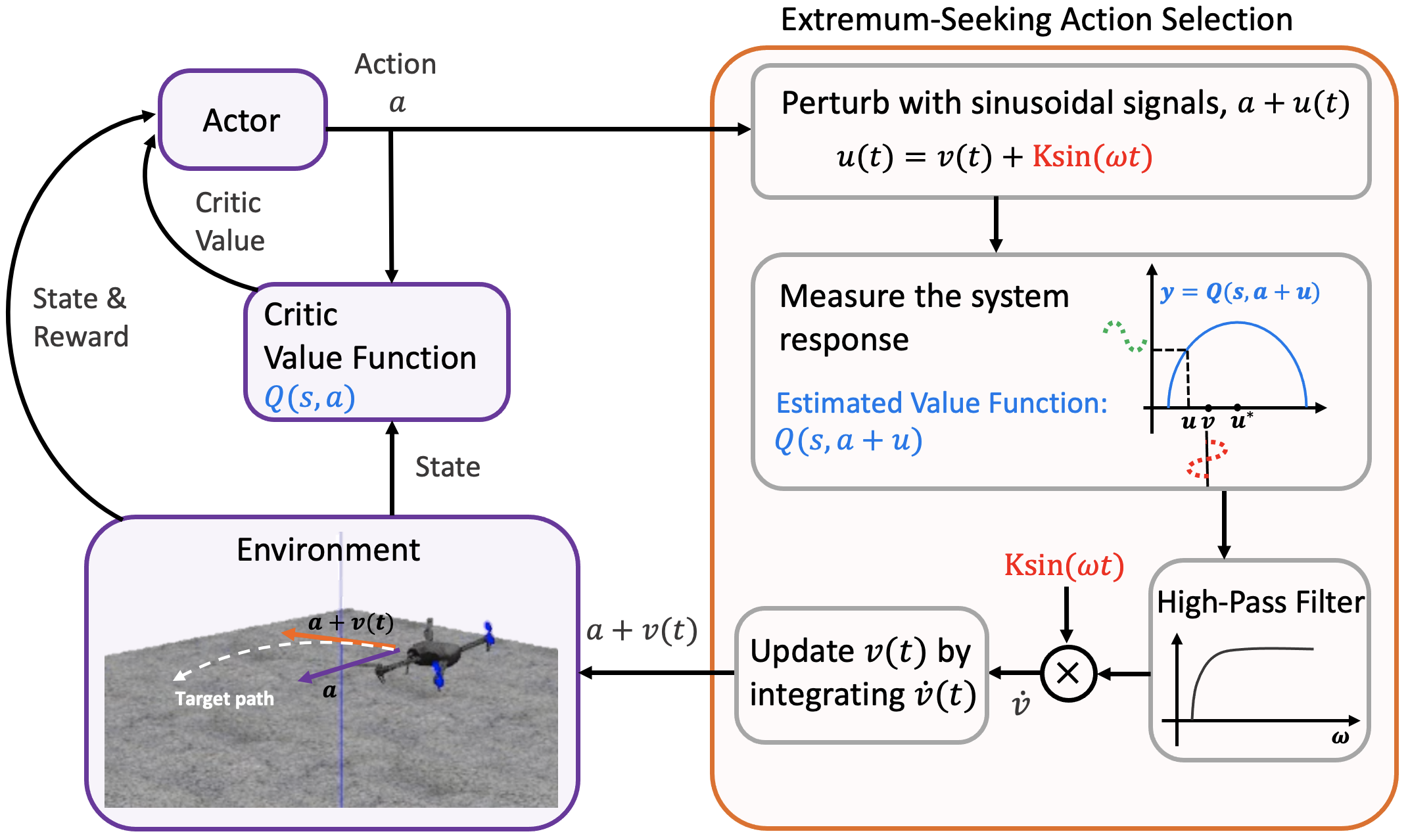
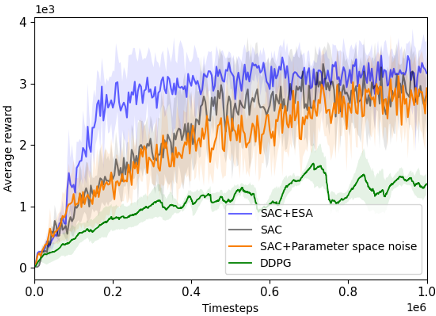
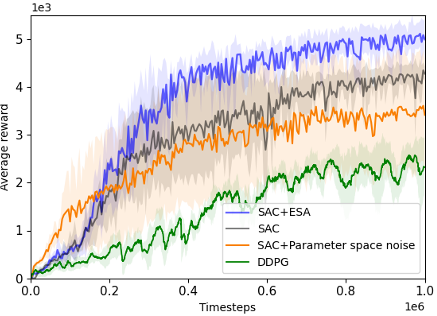
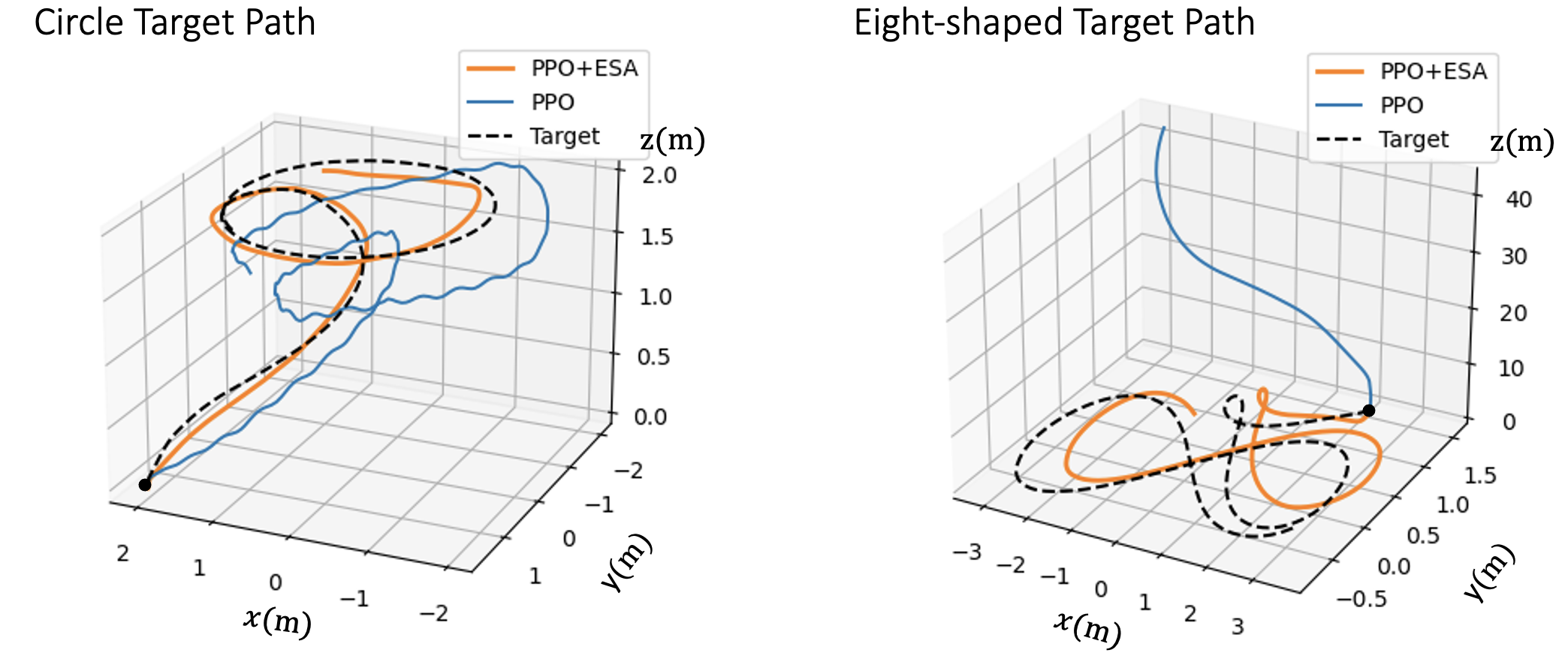
Overall Algorithm:
Extremum-Seeking Action Selection (ESA) in Reinforcement Learning
High-pass filters remove "flat" regions in the Q-value landscape, making it easier to locate actions that lead to local peak Q-values.
In the figure below, high-pass filters enhance the visibility of peaks, enabling faster local improvement towards the optimum.
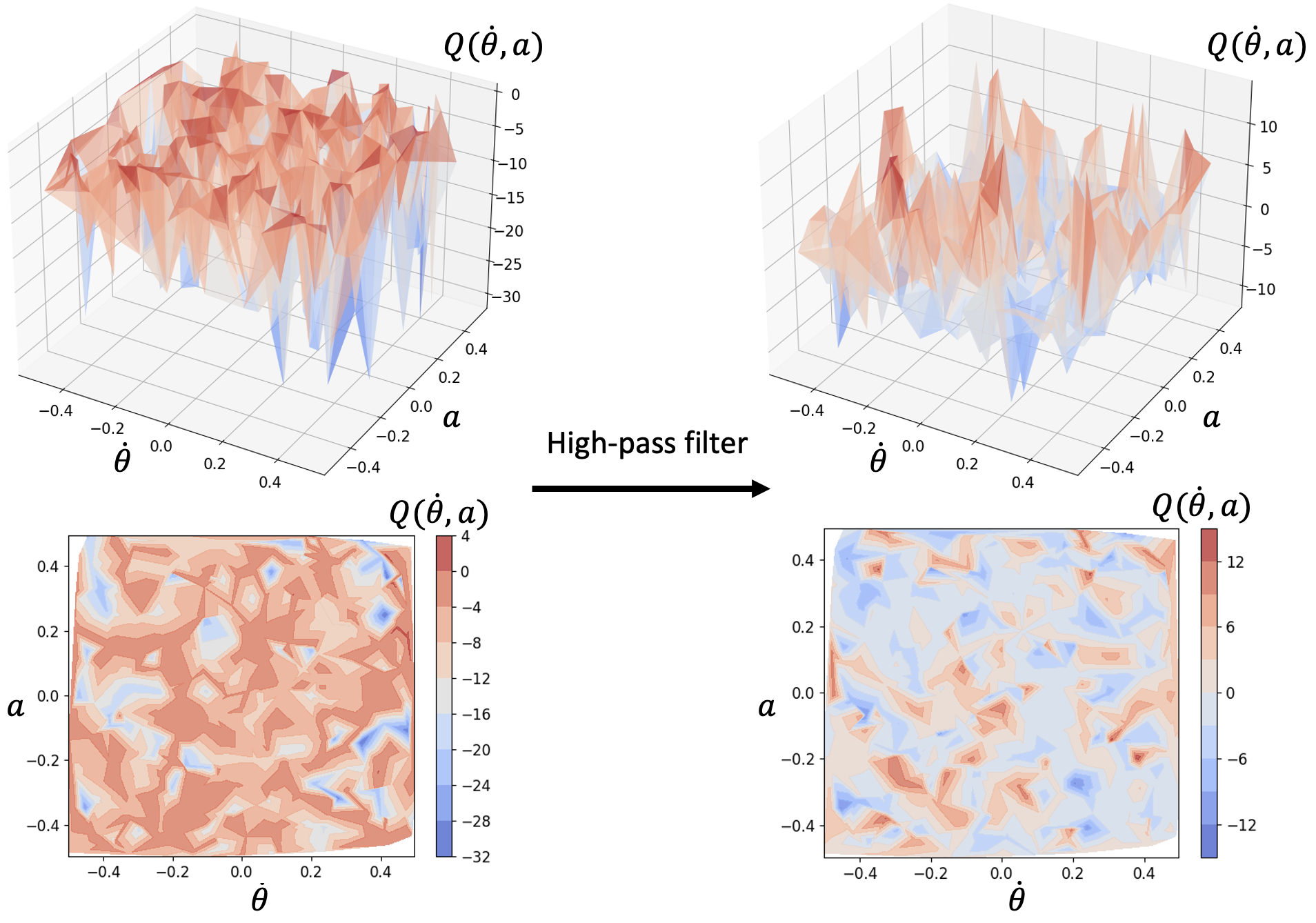
An illustration of the effect of using high-pass filters on the
Q-value landscapes in the inverted pendulum environment.
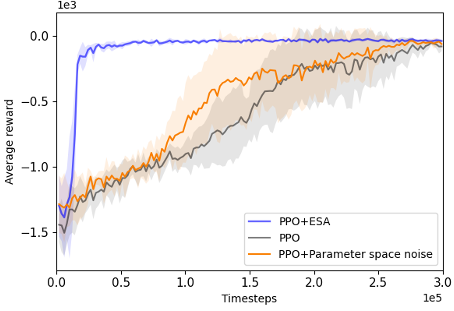
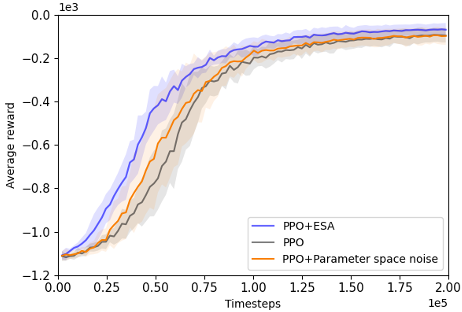
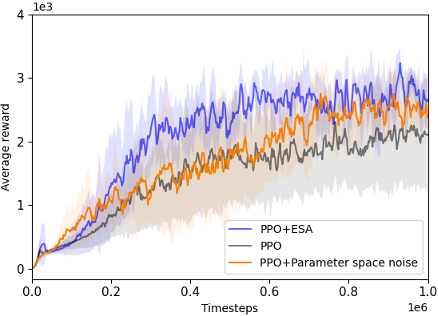
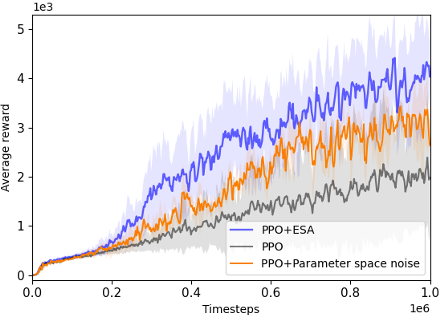
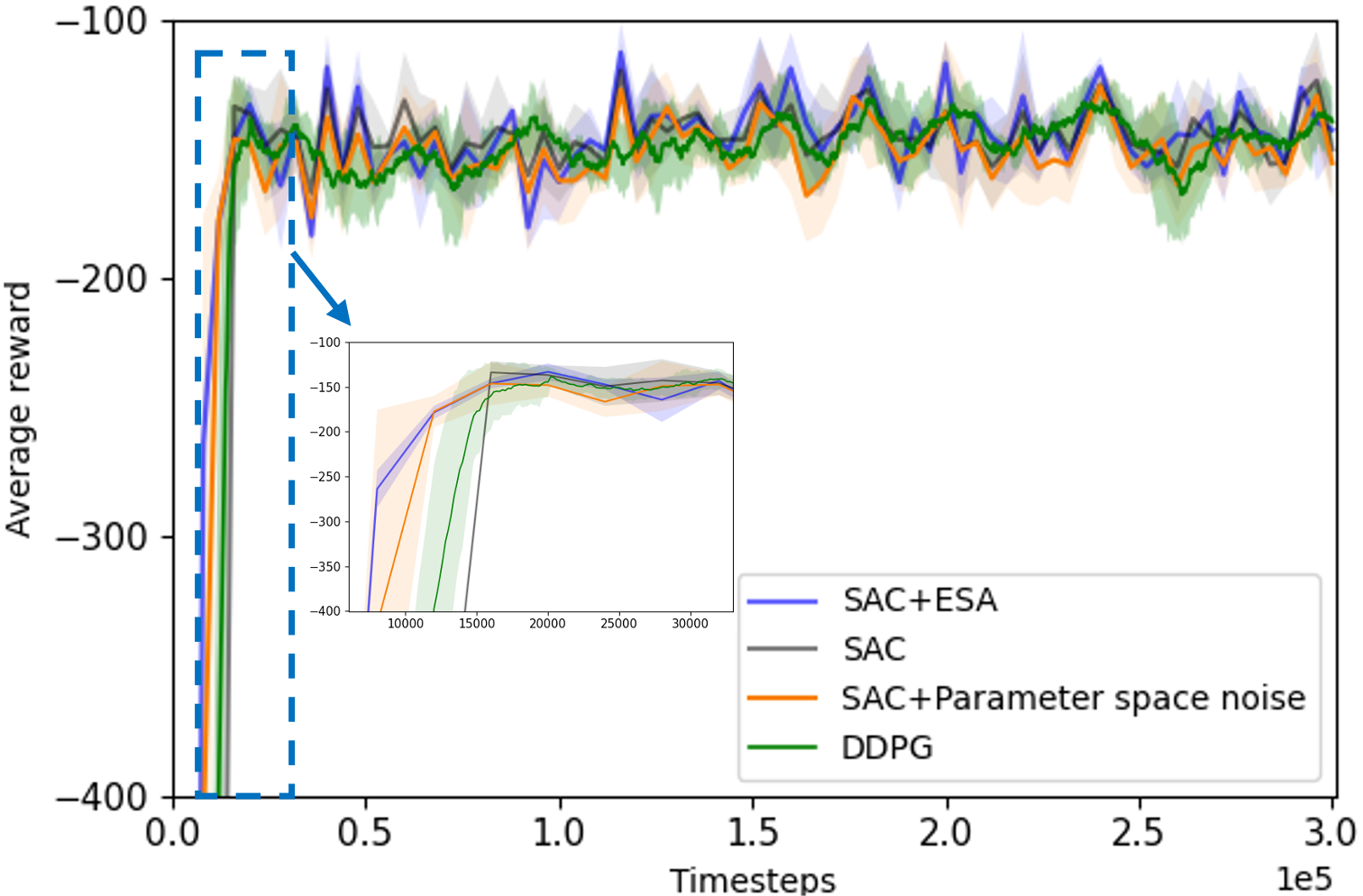
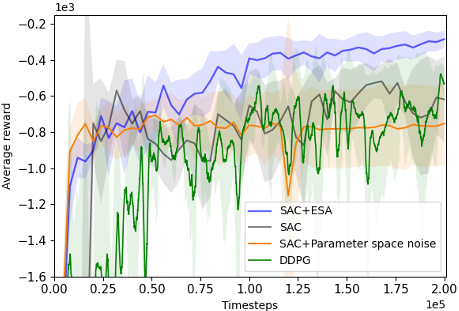
@inproceedings{chang2024esa,
title={Extremum-Seeking Action Selection for Accelerating Policy Optimization},
author={Chang, Ya-Chien and Gao, Sicun},
booktitle={2024 IEEE International Conference on Robotics and Automation (ICRA)},
year={2024},
organization={IEEE}
}